
Costruiamo il
futuro digitale
del tuo business.
Progettiamo sistemi digitali che uniscono AI, automazioni e marketing. Strumenti che evolvono con il tuo business e generano risultati concreti, ogni giorno.
Dentro l'Ecosistema
Triskell Ecosystem è il progetto-madre. Tre brand operativi, una sola visione.
Triskell Agency
Il braccio operativo dell'ecosistema. Sviluppo digitale con AI, campagne ADV, lead generation e gestione marketing per far crescere il tuo business.
Scopri Triskell Agency→Triskell Academy
Il polo formativo dell'ecosistema. Corsi pratici su AI, digital marketing, automazioni e business growth — insegnati da chi li applica ogni giorno.
Scopri Triskell Academy→Triskell Publishing
L'editoriale dell'ecosistema. Guide, ebook e libri per imparare AI, digital marketing e strategie digitali in autonomia.
Scopri Triskell Publishing→
Vibe Coding
La nostra guida gratuita
Da dove partire? Da qui. 10+ capitoli pratici per costruire con l'AI senza essere uno sviluppatore.
Scopri la Guida→Trova il tuo posto nell'ecosistema
Triskell Ecosystem si adatta al punto in cui sei. Riconosciti in uno di questi profili e scopri da dove partire.
← Scorri orizzontalmente per esplorare i profili →
3 step. Nessuna teoria. Solo sistemi che funzionano.
Che tu venga in Agency, Academy o Publishing, il nostro approccio è sempre lo stesso.
ASCOLTO & STRATEGIA
Capiamo dove sei, dove vuoi arrivare e cosa ti blocca davvero. Niente template, niente soluzioni pre-confezionate.
- ✓Audit gratuito iniziale
- ✓Roadmap chiara e personalizzata
- ✓Goal misurabili
COSTRUZIONE & TEST
Costruiamo il sistema su misura: AI, automazioni, contenuti, ADV. Lo testiamo prima su di noi, poi lo applichiamo al tuo contesto.
- ✓MVP funzionante e operativo
- ✓Team formato (se serve)
- ✓Asset consegnati e pronti all'uso
ACCELERAZIONE & CRESCITA
Misuriamo, ottimizziamo, scaliamo. Il sistema cresce con te, non si ferma alla consegna.
- ✓Performance attiva e monitorata
- ✓Iterazioni basate su dati reali
- ✓Crescita continua nel tempo
3 step. Nessuna teoria. Solo sistemi che funzionano.
Che tu venga in Agency, Academy o Publishing, il nostro approccio è sempre lo stesso.
ASCOLTO & STRATEGIA
Capiamo dove sei, dove vuoi arrivare e cosa ti blocca davvero. Niente template, niente soluzioni pre-confezionate.
- ✓Audit gratuito iniziale
- ✓Roadmap chiara e personalizzata
- ✓Goal misurabili
COSTRUZIONE & TEST
Costruiamo il sistema su misura: AI, automazioni, contenuti, ADV. Lo testiamo prima su di noi, poi lo applichiamo al tuo contesto.
- ✓MVP funzionante e operativo
- ✓Team formato (se serve)
- ✓Asset consegnati e pronti all'uso
ACCELERAZIONE & CRESCITA
Misuriamo, ottimizziamo, scaliamo. Il sistema cresce con te, non si ferma alla consegna.
- ✓Performance attiva e monitorata
- ✓Iterazioni basate su dati reali
- ✓Crescita continua nel tempo
Risultati reali con clienti reali

Forme Fitness
Come abbiamo costruito un sistema pubblicitario continuativo che genera contatti qualificati ogni mese — per 3 anni e in crescita

Urban Fitness Lecco
Una collaborazione nata dalla gestione delle campagne Meta Ads e cresciuta nel tempo fino a integrare social media, CRM, processi di follow-up, formazione commerciale e ottimizzazione continua.
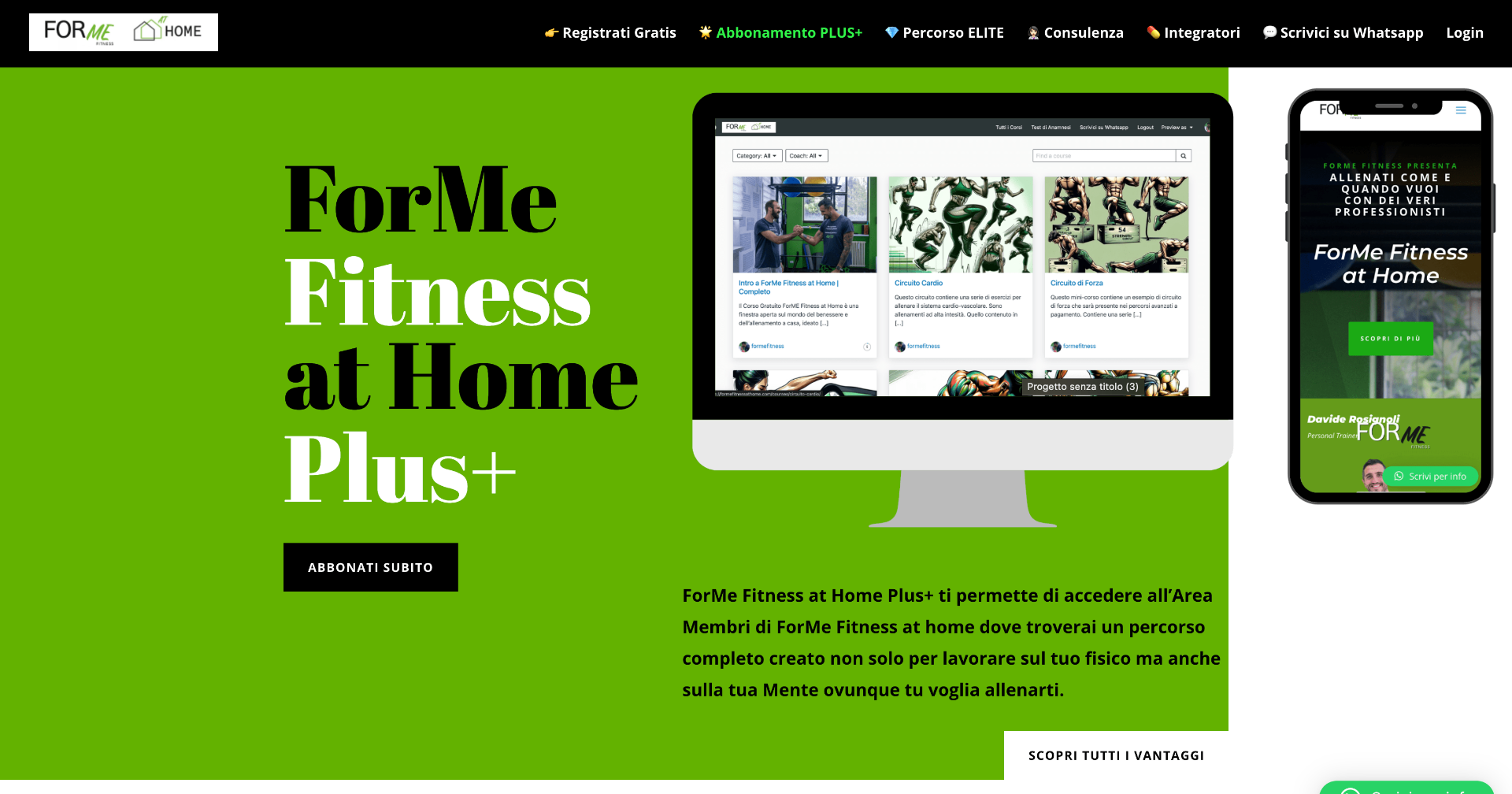
ForMe Fitness at Home
Un progetto nato per portare online il metodo ForMe Fitness e trasformarlo in una piattaforma digitale capace di vendere percorsi, gestire clienti e generare fatturato mensile ricorrente.
Guide Esclusive
Risorse pratiche scaricabili per far crescere il tuo business.
Laboratorio AI
Strumenti, prompt e workflow per innovare ogni giorno.
Entra nell'Area Membri
Accedi alla tua dashboard o registrati per entrare nell'ecosistema Triskell.
Community Privata
Confronto diretto con founder, creator e professionisti.
Aggiornamenti Continui
Nuovi contenuti e funzionalità rilasciati ogni mese.